
Year: 2012
Visualising the Ruby Global VM Lock
I’m working on Ruby bindings for Ceph’s RADOS client library – it’s the first native C Ruby extension I’ve written so I’m learning lots of new things.
I’m keen to ensure my extension releases Ruby’s Global VM Lock (GVL) wherever it’s waiting on IO, so that other threads can do work and I’ve written a few simple test scripts to prove to myself it’s working correctly. The result is a textual visualisation of how releasing the GVL can improve the behaviour of threads in Ruby.
For example, I just added basic read and write support to my library so you can read and write objects stored in a Ceph RADOS cluster. My first pass was written without releasing the GVL – it just blocks waiting until Ceph has completed the read or write.
My test script starts three threads, one doing rados write operations in a loop and outputting a “w” to STDOUT when they succeed, one doing rados read operations and writing a “r” and one just doing some cpu work in Ruby and writing a “.”
This is the output from the script before I added GVL releases:
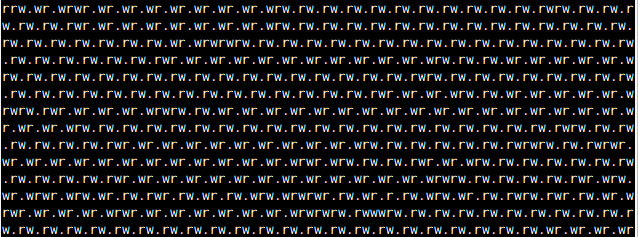
As you can see, it’s almost as if Ruby is switching round-robin style between the threads, waiting for each one to complete one iteration. In some cases, the cpu worker doesn’t get a look in for several read and write iterations!
So then I extracted the blocking parts out to a separate function and called them using Ruby 1.9’s rb_thread_blocking_region function, which releases the GVL, and then reran my test script:
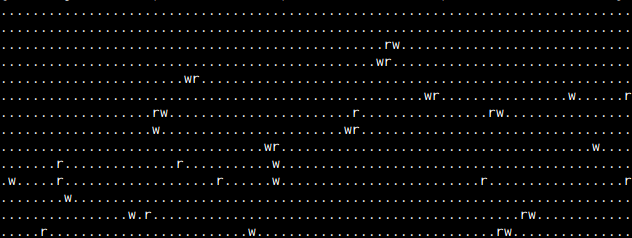
As you can see, the thread doing CPU work in Ruby gets considerably more work done when the GVL is released. Those network-based IO operations can block for quite some time.
It’s exactly what is expected, but it’s neat to see it in action so clearly.
The code for the library is here on github, but but it’s under heavy development at the moment and is in no way complete – I’ve only pushed it out so early so I can write this blog. And this is commit showing just where I made the read/write operations release the gvl.
Beautiful command-line interface design talk
I spoke about writing beautiful command-line interfaces at Scottish Ruby Conference back in June and they’ve published the video, which is freely available for viewing now.

The slides are available here in pdf format (if you’re interested, they were made using emacs org mode and beamer.
There were loads of great talks recorded so check out the videos of them all here on the schedule.
Domes on Mars – Pathfinder Mission
The recent NASA “Curiosity” mission that just landed reminded me of something I did the last time a robot was exploring up there.
It was July 1997, and I was 18 years old and relatively new to the Internet (having been knocking around it for only a couple of years at that point, by my recollection). I was a keen computer artist, using Lightwave 3D at the time.
So when the Mars Pathfinder robot landed and made big news, it was only natural that I rendered some domes onto the first photos they published and put them on the Internet, claiming them to be “The images NASA doesn’t want you to see”.
Much to my surprise, the counter on the free webspace I had with my Demon Internet dial-up account quickly starting increasing. Many hundreds of thousands of hits, which was a lot in those days (as it took 20 minutes just to connect to the Internet and the only way to find things was with gopher and downloading a photo was something you left running overnight and it all cost so much money, unless you used stolen “Red Hot Ant” free dialup numbers which everyone did all the time).
Anyway, long story short, it attracted lots of attention. I was interviewed live on some American crackpot Art Bell radio show (Atlanta’s WGST Planet Radio). I told them I found the images in the bins round the back of NASA). It was in magazines (well, one). And I became rich and famous and banned from ever visiting Mars.
Anyway, the Internet Archive has a copy of the text and I managed to find this one image some daft consipiracy website had kept a copy of. And here it is in all it’s glory.

And there began my long career of being a dick on the Internet.
UPDATE: The Way Back When machine is able to show my original site now and it has all my silly explanation of the origin of the photos (plus this bonus photo shows a figure stood in the distance)
UPDATE: I found an old backup of the images, plus some wireframes of the rendering I did to make the domes



UPDATE: I found an old issue of “Connect” magazine a friend gave me at the time, back when magazines still existed. Connect was basically just a list of links to funny stuff on the Internet this week and they reviewed the site in their Conspiracies section.

Talk: Top 10 distributed storage systems
I gave this talk at the FLOSS UK Spring conference in Edinburgh, in March 2012.
Louisa, Lily the dog and I went for a walk in the woods near my parents home in Heaton, Bradford and we came across the now closed down Heaton Royds school. It seems to have closed down around March 2009 and has been vandalised a number of times. I took a few photos and scared a fox who had apparently moved in.





















{kind=link}
{kind=link}
Rate limiting with Apache and mod-security
Rate limiting by request in Apache isn’t easy, but I finally figured out a satisfactory way of doing it using the mod-security Apache module. We’re using it at Brightbox to prevent buggy scripts rinsing our metadata service. In particular, we needed th e ability to allow a high burst of initial requests, as that’s our normal usage pattern. So here’s how to do it.
Install mod-security (on Debian/Ubuntu, just install the libapache2-modsecurity package) and configure it in your virtual host definition like this:
SecRuleEngine On
<LocationMatch "^/somepath">
SecAction initcol:ip=%{REMOTE_ADDR},pass,nolog
SecAction "phase:5,deprecatevar:ip.somepathcounter=1/1,pass,nolog"
SecRule IP:SOMEPATHCOUNTER "@gt 60" "phase:2,pause:300,deny,status:509,setenv:RATELIMITED,skip:1,nolog"
SecAction "phase:2,pass,setvar:ip.somepathcounter=+1,nolog"
Header always set Retry-After "10" env=RATELIMITED
</LocationMatch>
ErrorDocument 509 "Rate Limit Exceeded"Full text indexing of syslog messages with Riak
I’ve just released a little tool I wrote called riak-syslog which takes your syslog messages and puts them into a Riak cluster and then lets you search them using Riak’s full text search.
Rather than re-implement the wheel, riak-syslog expects that a syslog daemon will handle receiving syslog messages and will be able to provide them in a specific format – there is documentation on getting this running with rsyslog on Ubuntu.
I’ve used it to gather and store a few hundred gig of syslogs over the last several months on an small internal Riak cluster on Brightbox Cloud and it’s working well (which can’t be said of a similar setup I did with Solr which caved in after a while and needed some fine tuning!)
There is documentation on getting it set up in the README, and some examples of how to conduct searches too.
If you want to play with Riak, you can build a four node cluster spanning two data-centres in five minutes on Brightbox Cloud.
You might also be interested in my post about indexing syslog messages with Solr.
My dog Lily, asleeping

Understandably tired after a long day of sleeping.
Documentation that tells a story
When reading technical documentation I too often come across examples like this:
let’s assume you have a client called foo and a server called bar
or command examples like:
mysqldump -h server1 | mysql -h server2
When I write documentation, I prefer to tell a story. What is the client called, Steven? Are we taking a mysqldump of a production server and writing it to a staging server?
Human brains like stories. It’s much easier to keep track of facts if they have some kind of meaning. Many memory improvement techniques use stories to link things together. And when you’re reading documentation, you’re usually learning some new concept anyway – so you’re adding unnecessary cognitive load by using abstract labels like Foo and Bar or A and B.
In my Git submodules post I name the two example projects your_project and other_project and use it consistently throughout. You never have to rememeber whether “Foo” is the remote project or not.
One of my own favourites is an old heartbeat cluster guide I wrote. It involves two clusters, each of which consisted of two servers working together. I named the first cluster JuliusCaesar, naming the two nodes Julius and Caesar. The second cluster is called MarcusAurelius. Throughout the documentation, I’m able to refer to any server just by it’s name and you can know where it is in the network.
It’s part of why I like using rspec to do testing, because it encourages you to tell a story rather than to just test arbitrary values.
So, put some thought into your examples. Tell a story. Make it easier for the reader to keep track of all this new stuff they’re learning.