I’m working on Ruby bindings for Ceph’s RADOS client library – it’s the first native C Ruby extension I’ve written so I’m learning lots of new things.
I’m keen to ensure my extension releases Ruby’s Global VM Lock (GVL) wherever it’s waiting on IO, so that other threads can do work and I’ve written a few simple test scripts to prove to myself it’s working correctly. The result is a textual visualisation of how releasing the GVL can improve the behaviour of threads in Ruby.
For example, I just added basic read and write support to my library so you can read and write objects stored in a Ceph RADOS cluster. My first pass was written without releasing the GVL – it just blocks waiting until Ceph has completed the read or write.
My test script starts three threads, one doing rados write operations in a loop and outputting a “w” to STDOUT when they succeed, one doing rados read operations and writing a “r” and one just doing some cpu work in Ruby and writing a “.”
This is the output from the script before I added GVL releases:
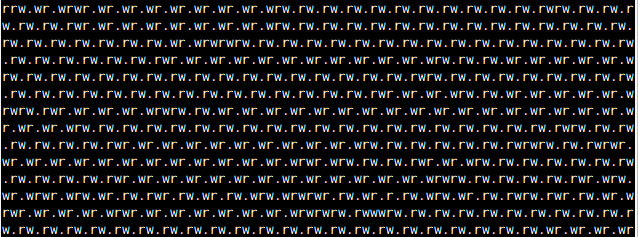
As you can see, it’s almost as if Ruby is switching round-robin style between the threads, waiting for each one to complete one iteration. In some cases, the cpu worker doesn’t get a look in for several read and write iterations!
So then I extracted the blocking parts out to a separate function and called them using Ruby 1.9’s rb_thread_blocking_region function, which releases the GVL, and then reran my test script:
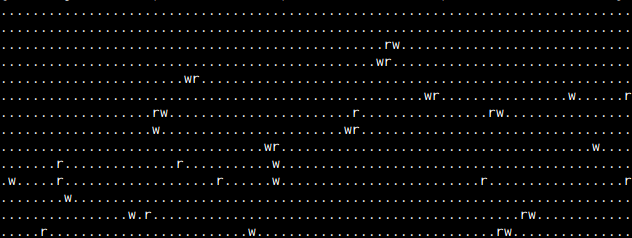
As you can see, the thread doing CPU work in Ruby gets considerably more work done when the GVL is released. Those network-based IO operations can block for quite some time.
It’s exactly what is expected, but it’s neat to see it in action so clearly.
The code for the library is here on github, but but it’s under heavy development at the moment and is in no way complete – I’ve only pushed it out so early so I can write this blog. And this is commit showing just where I made the read/write operations release the gvl.
